
Table of Content
1. Introduction
2. Scenarios leading to missing-label instance
3. Background
4. YOLO's performance declination by missing labels
5. Addressing YOLO's performance degradation
1. Introduction
Modern CNN-based object detectors such as faster R-CNN and YOLO achieve remarkable performance when trained on fully labeled large-scale datasets. On the one hand, collecting a dataset with full annotations, specifically bounding boxes around Objects of Interest (OoI), can be a tedious and costly process. On the other hand, the object detectors such as R-CNN and YOLO show that their performance is dependent on having access to such fully labeled datasets. In other words, training them on partially labelled datasets (i.e. containing instances with missing-labels) leads to a drop in generalization performance.
2. When do datasets for object detection tasks contain missing-label instances?
Several scenarios can lead to a partially labelled dataset:- Unintentional error in labelling
- Partial annotation policy : Aim to reduce annotation cost, "partial annotation policy" considers to annotate only one instance of each object presented in a given image. For example, in an image containing a herd of sheep, only one sheep is annotated, instead of fully annotating all the sheep instances in the image. This policy causes some missing bounding box annotations but interestingly no missing image-level labels as at least one instance of each existing object in the given image is annotated.
- Merged dataset: Combining several datasets from similar (or the same) contexts but with disjoint
(or partially disjoint) sets of Objects of Interest (OoI) for quickly constructing a larger dataset that
includes a wider range of objects of interest. For instance, Kitti and BDDK100 are
two different datasets for roads with two disjoint sets of OoIs that could be merged to cover a wider spectrum of variations (light, style, and etc ) and various road objects.
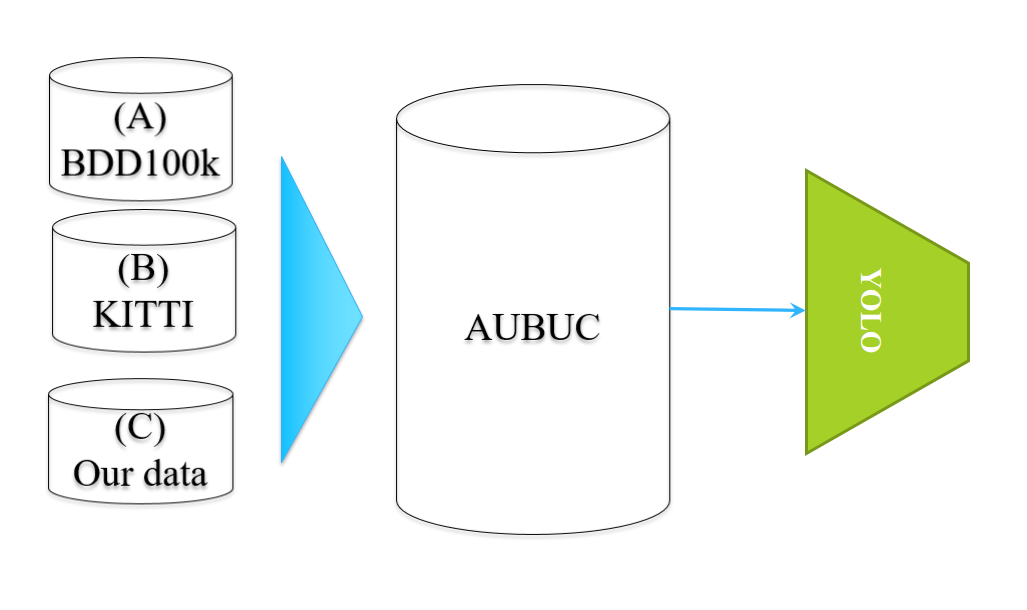 Figure 1: Merging several datasets to quickly building a larger dataset with wider range of variations and object of interest.
Figure 1: Merging several datasets to quickly building a larger dataset with wider range of variations and object of interest.
3. Background
Before explaining how missing-label instances, which we call them Unlabelled Positive Instances (UPIs), do negatively influence the performance of YOLO, let to briefly explain some elements of YOLO along with their notations.
YOLO divides a given image $I$ into $g\times g$ grids, then for each grid $G_{ij}$, it estimates $A$ different bounding-boxes, where each of them is a $5+K$-dimensional vector, encompassing the estimated coordinate information of the box ($\mathbf{r}^a_{G_{ij}}=\left[\hat{x}^a_{G_{ij}},\hat{y}^a_{G_{ij}}, \hat{w}^a_{G_{ij}}, \hat{h}^a_{G_{ij}} \right]$), the objectiveness probability ($p(O|\mathbf{r}^a_{G_{ij}})$), and a $K$-dimensional vector as the probabilities over $K$ object categorizes ($\textbf{p}(c|\mathbf{r}^a_{G_{ij}})\in[0,1]^K$) with $a\in\{1,\dots A\}$. Therefore, the output of YOLO will be a tensor of size $\left[g,g,A,5+K\right]$. Moreover, for each grid ${G_{ij}}$, a set of pre-defined bounding-boxes (called anchors) with different aspect ratios and scales is considered. YOLO learns to estimates the bounding-boxes w.r.t these pre-defined anchors.
Three kinds of losses
- Object loss aims to enforce YOLO to predict the existence of an object of interest (OOI) inside a given anchor, i.e. $p(O|\mathbf{r}^a_{G_{ij}})$.
- Class loss predicts the category of an OOI
- Coordinate loss encourages YOLO to esitmate precisely the coordinate of ROIs involving an OOI.
4. How do missing-label instances degrade detection performance?
While UPIs do not contribute to the training of YOLO through their class and coordinate losses, they can adversely contribute through their object loss. In other words, object loss is computed for all anchors of all grids, whether they contain any ground-truths or not. This is not the case for class and coordinate losses. Therefore, computation of object loss for the UPIs creates false-negative training signals, leading to a degradation of performance. More specifically, during training of YOLO, the detector may be able to correctly localize an UPI, estimating its corresponding anchor with $p(O)\sim1$. But, due to the absence of a ground-truth label associated to an UPI, its true object label is considered zero, i.e. $t=0$, by default, causing YOLO to be penelized incorrectly. Indeed, such a false-negative training signal forces the network to learn an UPI as a negative or not-interesting object even though the model already correctly localize and recognize it. Ultimately, such false negative signals from UPIs can confuse the network; while LPIs (Labelled Positive Instance) of the same object category forces the network to learn it as an object of interest, such UPIs (from the same object category) encourage the network to learn it as a not-interesting (negative) object. Finally, such false-negative signals can cause a drop in the performance of YOLO.
5. How to overcome such a performance degradation?
Generally speaking, there are two solutions for this problem arise from UPIs; ignore the false negative signals (Wu et. al. ) or correct them. In our article , we not only correct these false-negative signals, which are aroused from the object loss but also create more training signals from the coordinate and class losses through generating some pseudo-labels for the UPIs. To read a short description of our self-supervised method, click here .