Table of Content
HomeSelf-supervised framework for generating pseudo-labels
1. Introduction
In previous blog post, we explained how missing-label instances or UPIs (Unlabelled Positive Instances) can create false negative signals, causing performance declination of a modern object detector, e.g. YOLO. Here, we propose to mitigate this challenge through generating pseudo-labels for the UPIs to reduce the number of false negative signals.
Briefly, our method is an end-to-end solution, meaning that during training of YOLO, it recognizes UPIs, then generates pseudo-labels. To this end, we incorporate a pre-trained proxy model (Augmented CNN-- a vanilla CNN with an extra class added to its output) to indicate whether the ROIs estimated by YOLO (during its training) contain an object of interest or not. If the proxy model classifies an ROI as its extra class (meaning it contains a not-interesting object), it is discarded, otherwise, the coordinate information of ROI along with its estimated class and its associated confidence provided by A-CNN are considered as a pseudo-label.
In Fig 1, we show the overall pip-line of our proposed method for generating pseudo-labels during training YOLO, where it simultaneously is trained on both ground truths and the generated pseudo-labels.
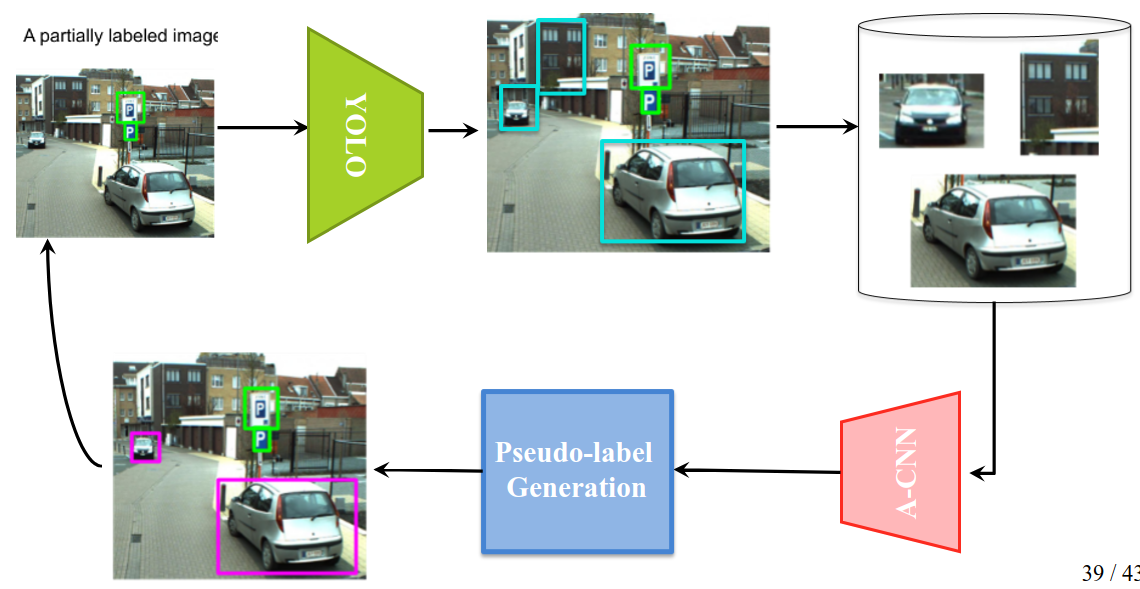
2. Our framework in nutshell
In this post, we briefly explain the stages of our proposed framework. Please refer to our Arxiv paper to read with more details.- Stage 1: in training phase (at a given epoch), YOLO outputs some estimated ROIs, which may (may not) contains an OOI. These ROIs from the given image are extracted.
- Stage 2: feeding a pre-trained A-CNN with the extracted ROIs, they are classified as one of the pre-defined categories (corresponding to the categories of objects of interest) or reject them (equivalent to the A-CNN's extra class). The ROIs that are classified confidently as one of the pre-defined categories are forwarded to the next stage.
- Stage 3: for the ROIs passed from the previous stage, we generate new pseudo-labels, each label includes the coordinate info of a ROI, objectness score, and category. Two latter values are the maximum predictive confidence and its corresponding class estimated by A-CNN for the given ROI.
- Stage 4: the generated pseudo-labels and the ground truth are collectively used for training YOLO.
2.1. Tricks
There are some tricks related to A-CNN to get the above framework working.
Extracted ROIs with different sizes
Originally, the CNNs that have some FC layers can not process inputs with different sizes since the FC layers in the architecture can accept the inputs with identical size. However, feeding the convolution layers with different sizes incur outputs with different sizes, which are then passed to the successive FC layer in such an architecture. To address this issue, SPP (Spatial Pyramid Pooling) layer is proposed, which allows a CNN process inputs data with various sizes. Using SPP, we then able to process the ROIs with different sizes. However, from technical view point (pytorch), we can not have a batch of inputs with different sizes. To circumvent this challenge, we used "k-means trick" so that minimized the zero-pad added to the images. In this trick, the input samples with different sizes are clustered so that the samples with similar sizes are placed in a cluster. Then, the samples of a cluster are padded so that they all have an identical size. Note that simply using naive padding, i.e. padding images to all have size of the largest image, is not recommended since it can create inputs with immense zero-margin, especially for tiny images.
Generate pseudo-labels only for the confident predictions
To create high confidence prediction, we used patch-drop to create different versions of an ROI, then averaging their predictions by the A-CNN, which then lead to better predictions in terms of calibration and reducing error. Later, we accept only those predictions with high confidence (larger than a threshold). Therefore, the chance of misclassification can be reduced, avoid generation of incorrect pseudo-labels.